Building a Medication Reminder System with Voice AI Agents, Telephony, and LLM-Assisted Development
This documents a recent project to provide telephone call reminders for someone to take their medications—with the kind of technology I’m most excited about right now: voice AI agents, speech-to-text (STT), text-to-speech (TTS), large language models (LLMs), and telephony integrations (e.g., Twilio).
The Problem: Reminders That Actually Reach People
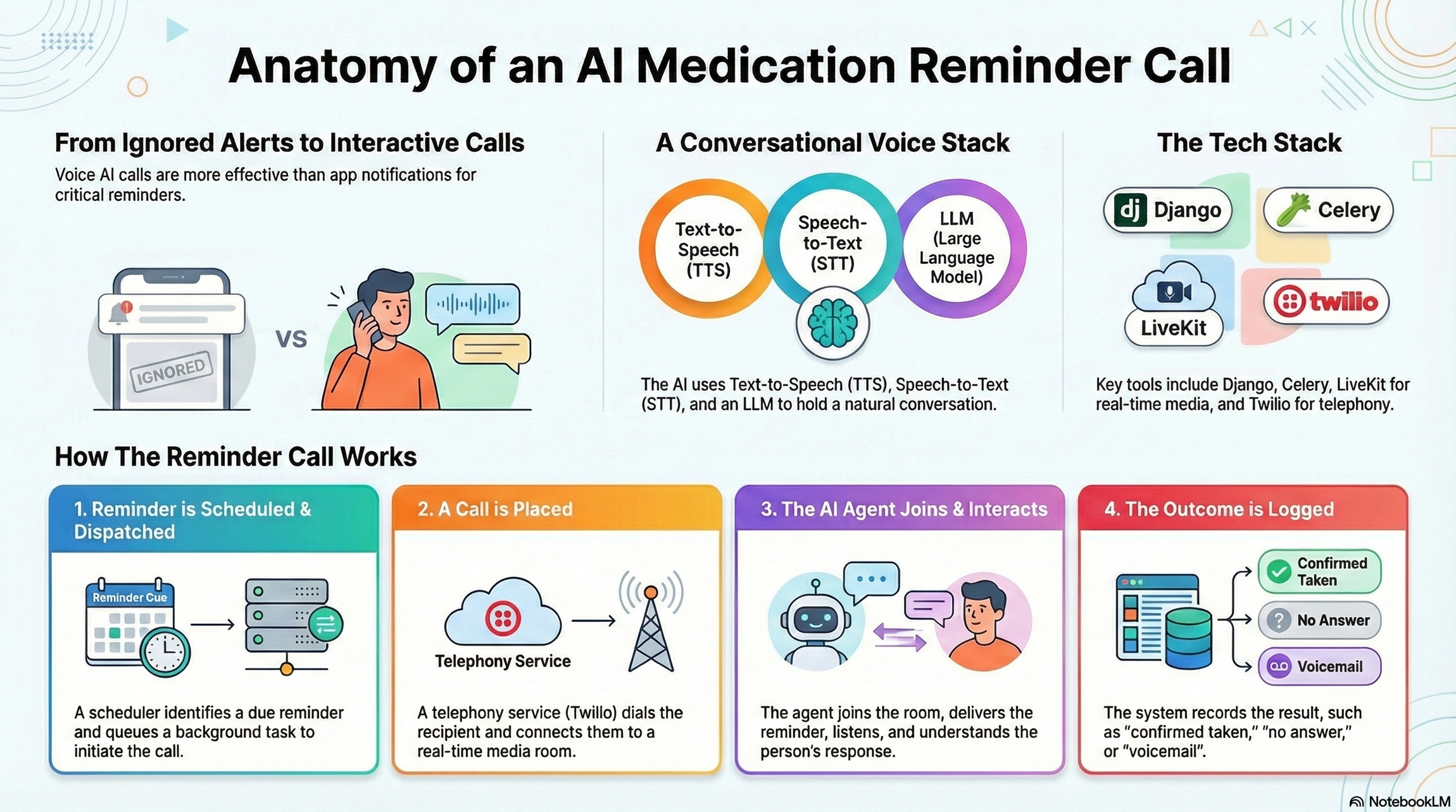
Notifications and app reminders are easy to ignore. But for many people—especially those who don’t live inside a smartphone all day—an actual phone call can be far more reliable. The core idea of this project is simple:
place a telephone call at the right time and deliver a friendly, clear reminder to take a medication.
A voice call also creates an opportunity for interaction. If the person answers, the system can confirm whether they took the medication, handle a quick follow-up question, and record the outcome—turning reminders into a lightweight check-in rather than a one-way alert.
Voice AI Reminder Agent
The system allows users to schedule reminders to recipients and then uses a voice AI agent to run the actual phone call. The agent can speak naturally, listen to responses, and adapt the conversation. This is where the “voice stack” comes in:
- TTS (Text-to-Speech) to generate spoken prompts (the agent’s voice).
- STT (Speech-to-Text) to transcribe what the person says.
- LLM to interpret intent and decide what to say next.
The result is a call that feels more like a simple conversation than a robotic IVR tree. The agent can handle variations like:
“I already took it,” “Yes I will take it”, etc.
This project uses Livekit Agent which makes it relatively easy to bring together all of the components needed for the voice AI agent: telephone SIP, connecting agent and recipient, in additiion to observability.
Telephony: Connecting AI to Real Phone Calls (Twilio + SIP)
A key part of the project is bridging modern real-time voice AI with the phone network. The goal isn’t just “voice in a browser”—it’s calling real phone numbers reliably.
Telephony providers like Twilio make it possible to originate or receive calls, while SIP-based connectivity and real-time media infrastructure handle the audio streaming to/from the agent. That pipeline lets the AI participate in the call as a real-time voice participant.
Getting this right involves a bunch of practical engineering details: call setup, routing, handling voicemail, retries, hangups, latency, and making sure the agent joins the call at the correct moment with the correct context.
System Overview: Scheduling + Dispatch + Conversation
Here’s the mental model I use for the architecture:
- Scheduling determines when a reminder should trigger (including recurrence rules and time zones).
- Dispatch creates/targets a call session and hands the agent the context it needs (who to call, what medication, what to say, and how to log outcomes).
- Conversation runtime runs the live call: speak → listen → understand → respond, while recording outcomes and events.
I’m building this with a strong emphasis on observability—being able to answer questions like: Did the call connect? Did the agent join? What did the user say? What outcome was recorded? Where did the failure happen if something went wrong?
Why Voice AI Agents Are So Interesting
Voice agents sit at a fascinating intersection of real-time systems and applied AI. You’re juggling:
- Real-time audio (latency matters; interruptions happen).
- Turn-taking (when to speak, when to pause, when to listen).
- Language understanding (intent extraction and ambiguity).
- Reliable task completion (the system must actually deliver a reminder and log results).
Unlike a chat interface, a phone call is synchronous and time-sensitive—there’s no “I’ll respond later.” That constraint forces you to build tighter control loops and better fallbacks.
LLM-Leveraged Development: Building Faster
I have been heavily leaning into LLM-assisted development as part of the workflow. Not in a “generate an entire app in one shot” way, but in a practical, engineering-focused way:
- Rapid prototyping of dialogue flows and agent behaviors.
- Faster iteration on error handling, logging, and edge cases.
- Refactoring help (naming, structure, decomposition) to keep the codebase maintainable.
- Generating test scenarios and checklists for tricky operational issues.
The important part is pairing speed with discipline: reviewing changes, keeping clean boundaries between components, and building a system that’s dependable—not just impressive in a demo.
Privacy, Safety, and Practical Constraints
Anything involving healthcare-adjacent reminders and phone calls deserves extra care. The project is being built with a “minimum necessary data” mindset and clear operational guardrails:
- Data minimization: store only what’s needed to schedule calls and log outcomes.
- Clear call behavior: avoid making the call feel deceptive; the experience should be transparent and respectful.
- Fallbacks: if the AI is uncertain, it should ask a clarifying question or gracefully end the call.
- Auditability: maintain call logs/outcomes so failures can be diagnosed and fixed.
Voice AI is powerful, but reliability and user trust are non-negotiable—especially when the goal is to support someone’s daily routine.
Technical Details
If you’re interested in how this is put together under the hood, here’s a more technical breakdown of the stack, the call flow, and some of the practical STT/TTS considerations that show up once you move from demos to real phone calls.
1) Tech Stack
- Backend (Django) — Holds the core data model (recipients, reminders, schedules, and call logs) and exposes endpoints for internal orchestration and provider callbacks/webhooks.
- Task queue (Celery) — Runs background work like “dispatch a call now”, retries, and any call-followup processing that shouldn’t block web requests.
- Scheduling trigger (cron) — A cron-triggered job kicks off “what reminders are due?” evaluation on a predictable cadence (e.g., every minute), then enqueues Celery tasks for the ones that should fire.
- Real-time media + voice agent runtime (LiveKit) — LiveKit provides the real-time room where the call audio can be streamed to/from the AI agent as a participant, enabling low-latency turn-taking and speech pipelines.
- Telephony provider (Twilio) — Used to place real outbound calls to PSTN phone numbers and bridge them into the real-time media environment (commonly via SIP-style connectivity and provider webhooks for call status).
- Agent side (Python) — The voice agent runs as its own service/process, connects to LiveKit, joins rooms when dispatched, and coordinates STT → LLM → TTS in real time.
- Persistence — A relational DB stores reminder schedules, recipient details, and call logs (including outcomes and optional transcripts) for auditability and troubleshooting.
2) Call Flow: Reminders → Calls → Logs → Outcomes
The operational loop looks roughly like this:
- Reminder becomes dueA scheduler checks for reminders that should fire now (based on schedule/recurrence rules and time zones).
- Dispatch is enqueuedA Celery task is queued to start the call workflow. This keeps the web process responsive and makes retries straightforward.
- Create/identify a LiveKit roomEach call session maps to a LiveKit room (often one room per call). The room is the shared “meeting place” where both the phone-side participant and the AI agent appear.
- Twilio places the phone callTwilio dials the recipient’s number. When the call connects, the PSTN audio is bridged so the phone participant effectively shows up in the LiveKit room.
- Agent joins the roomThe voice agent is dispatched to that specific room (with metadata like recipient info, the medication reminder text, and an internal call-log identifier). When it joins, it begins the conversation loop.
- Conversation + intent handlingThe agent delivers the reminder, listens for confirmation, and handles common responses (confirm taken, not taken, delay reminder, questions, etc.). The agent prioritizes clarity and short turns because phone audio is bandwidth-limited and people interrupt.
- Call logging + outcomeA call log is updated throughout the session: initiated → ringing → connected → completed/failed, plus structured outcomes (e.g., “confirmed taken”, “no answer”, “voicemail”, “requested retry in 10 minutes”), and optionally a transcript snippet for debugging.
This “room + call-log” pairing is useful because it gives you a clean boundary for debugging:
if a call is silent, you can check (a) did the phone participant join the room, and (b) did the agent join the room, and (c) did audio tracks publish/subscribe correctly.
3) TTS / STT: Practical Considerations
Speech systems behave very differently in the real world than in controlled demos. A few of the key considerations that come up when building a reliable reminder caller:
- Latency budget matters — The time from user speech → transcription → LLM decision → spoken response has to be short enough to feel conversational. Long pauses feel like the system “broke”.
- Bararge-in / interruption handling — People interrupt. A good agent needs to stop speaking when the user starts talking (or at least detect overlap) and recover gracefully.
- Telephone audio is constrained — PSTN quality is narrowband and noisy compared to studio audio. That affects both STT accuracy and how natural TTS sounds. You often need shorter phrases and stronger confirmations.
- Confirmation loops — For medication reminders, you want simple, explicit confirmations (“Did you take it now?” / “Should I call back in 10 minutes?”). This reduces ambiguity and helps the system log outcomes reliably.
- Noise, accents, and speaker variability — STT needs to tolerate background noise, different speech patterns, and low-volume speakers. In practice you design the dialogue so the agent can ask clarifying questions without feeling annoying.
- Voicemail detection and fallbacks — If voicemail picks up, the system should switch strategies: leave a short message (if appropriate) and log “voicemail”, rather than entering an interactive conversation loop.
- Transcript storage tradeoffs — Transcripts are extremely useful for debugging, but they can also be sensitive. A common approach is to store minimal structured outcomes by default and make transcripts optional and tightly controlled.
The big theme here is reliability: voice AI is only helpful if it consistently joins calls, speaks clearly, understands enough to capture a useful outcome, and fails in predictable ways when something goes wrong.